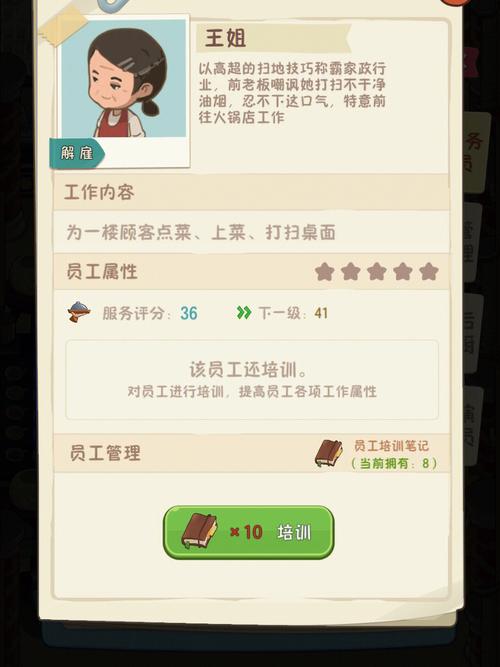
正则表达式在处理多行 HTML 文本时,出现只能捕获到最后一行的情况,这让许多开发者感到困惑,究竟是什么原因导致了这种现象呢?
要理解这个问题,我们需要先明确正则表达式的工作原理,正则表达式是一种用于模式匹配和文本操作的强大工具,它通过特定的规则和模式来查找和处理文本中的信息。
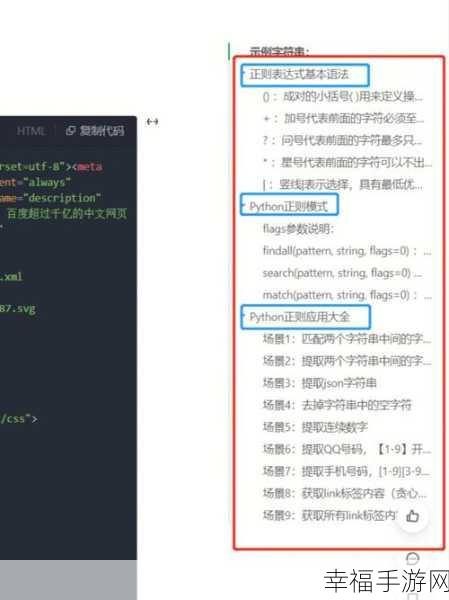
在处理多行文本时,正则表达式的默认行为可能与我们的预期有所不同,正则表达式的某些操作符和选项可能没有正确设置,导致无法完整捕获多行的内容。
HTML 文本本身的结构和复杂性也会给正则表达式的匹配带来挑战,HTML 包含各种标签、属性和特殊字符,这可能干扰了正则表达式的正常匹配过程。
为了解决这个问题,我们可以尝试调整正则表达式的模式和选项,使用特定的修饰符来启用多行匹配模式,或者更精确地定义匹配的规则,以适应 HTML 文本的特点。
对于复杂的 HTML 文本,可能需要结合其他的文本处理技术和工具,如解析库或特定的 HTML 处理函数,来更有效地提取所需的信息。
要解决正则表达式匹配多行 HTML 文本时只能捕获最后一行的问题,需要深入理解正则表达式的机制,结合 HTML 文本的特点进行针对性的调整和优化。
参考来源:相关技术论坛及专业文档。