SQL 查询结果,一直以来都让众多开发者和数据处理人员充满好奇与疑惑,它真的是随机的吗?这并非一个简单的问题,其背后隐藏着复杂的机制和原理。
要深入探究 SQL 查询结果的随机性,我们得先了解数据库的工作原理,数据库在处理查询请求时,会依据一系列的规则和算法来确定返回的结果集,这些规则和算法并非完全随机,而是受到多种因素的影响。
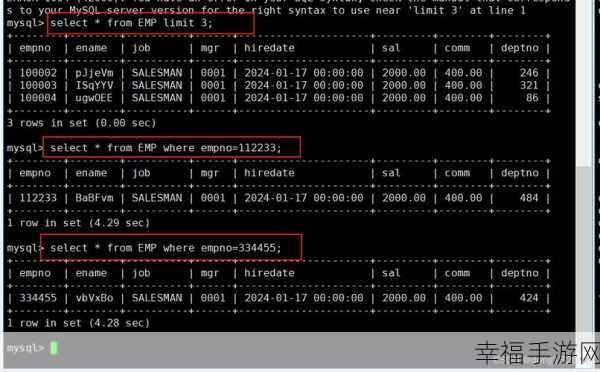
数据的分布、索引的使用以及查询语句的编写方式等,都会对最终的查询结果产生影响,如果数据本身分布不均匀,或者索引设置不合理,那么查询结果可能就会给人一种“随机”的错觉。
不同的数据库管理系统对于随机性的处理方式也可能存在差异,有些系统可能会提供特定的函数或选项来实现更可控的随机结果,而另一些系统则可能在默认情况下就有着独特的随机性处理机制。

为了验证 SQL 查询结果是否随机,我们可以进行一系列的实验,通过设计不同的数据结构、执行多种查询语句,并对结果进行分析和比较,就能逐步揭开这一谜团。
在实际应用中,了解 SQL 查询结果的随机性对于优化数据库性能、提高数据处理的准确性和可靠性至关重要,只有掌握了其内在规律,才能更好地利用数据库为我们的业务服务。
参考来源:相关数据库技术资料及实践经验总结。
仅供参考,您可以根据实际需求进行调整和修改。