在当今数字化时代,数据量呈爆炸式增长,如何有效地处理海量数据成为了众多领域面临的重要挑战,处理海量数据并非易事,它需要我们具备清晰的思路和有效的方法,就让我们一同深入探索处理海量数据的基本思路。
处理海量数据的核心在于建立高效的数据存储和管理体系,只有确保数据能够被妥善存储和组织,才能为后续的处理和分析打下坚实基础,这就要求我们根据数据的特点和应用需求,选择合适的数据库类型,如关系型数据库、非关系型数据库或分布式数据库等,还要注重数据的索引和分区策略,以提高数据的查询和检索效率。
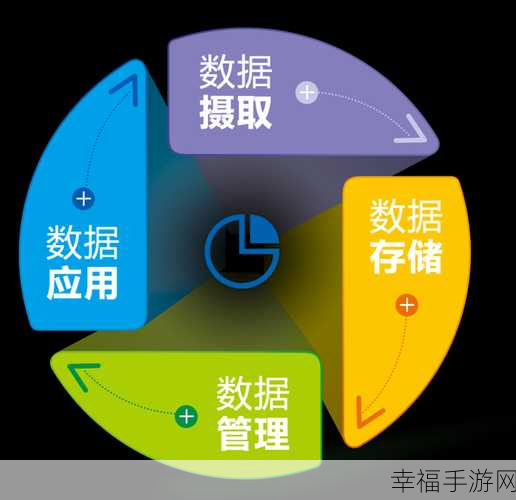
对数据进行预处理和清洗也是至关重要的环节,原始数据往往存在着各种噪声、缺失值和错误,若不加以处理,将会严重影响后续分析的准确性和可靠性,通过数据清洗、转换和归一化等操作,可以去除无效数据,纠正错误,并将数据转化为便于处理和分析的格式。
在处理海量数据时,合理运用分布式计算框架是一个有效的策略,Hadoop 生态系统中的 MapReduce 框架,能够将大规模数据处理任务分解为多个小任务,并在多个节点上并行执行,从而大大提高处理速度和效率,Spark 等新兴的分布式计算框架也提供了更强大的功能和更高效的处理方式。
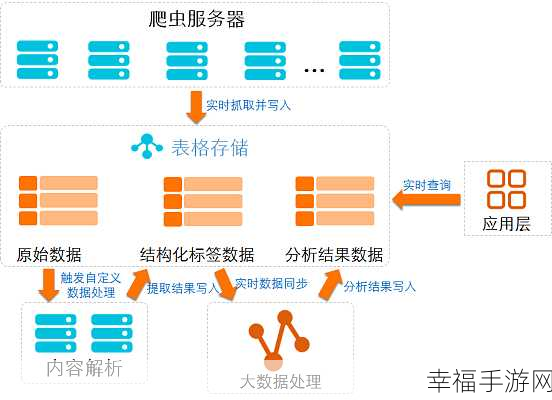
数据分析和挖掘算法的选择也是决定处理效果的重要因素,不同的算法适用于不同的数据类型和处理需求,我们需要根据具体情况进行选择和优化,为了不断提升处理效率和准确性,还需要对算法进行持续的改进和创新。
处理海量数据需要综合考虑数据存储、预处理、计算框架和算法选择等多个方面,只有在每个环节都采取科学合理的策略和方法,才能应对海量数据带来的挑战,实现数据的有效利用和价值挖掘。
文章参考来源:相关领域的学术研究及实践经验总结。