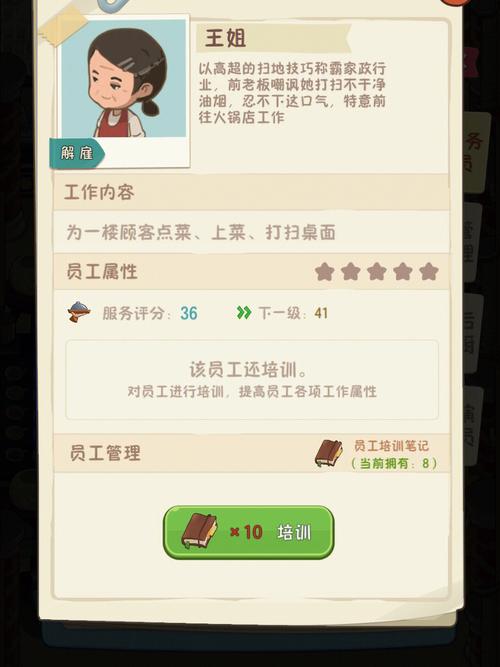
在当今数字化时代,处理大量数据是常见的任务,当涉及到在 Linux 系统下处理大数据文件,并需要删除其中部分字段的重复行时,掌握正确的方法至关重要。
想要实现这一目标,我们首先要明确文件的结构和重复行的特征,这是整个操作的基础,只有清楚了解这些,才能有的放矢地进行后续处理。
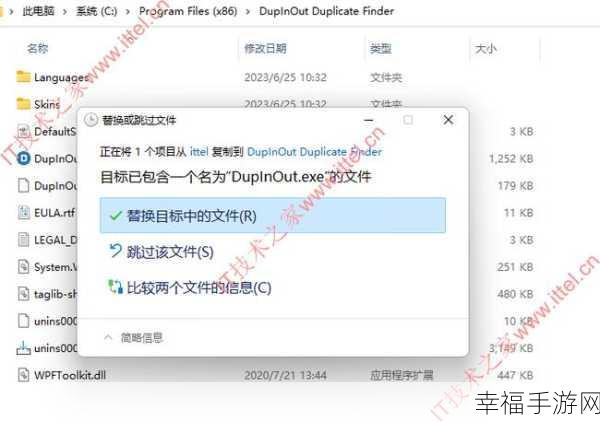
运用合适的命令和工具是关键,使用“sort”命令对文件进行排序,然后结合“uniq”命令来识别和删除重复行,通过这两个命令的巧妙配合,可以大大提高处理效率。
在实际操作中,还需注意参数的设置,不同的参数会影响命令的执行效果,要根据具体的文件情况和需求进行调整,以确保达到预期的删除效果。
为了避免误操作导致数据丢失或错误处理,在执行删除操作之前,建议先对文件进行备份,这样,即使出现意外情况,也能够及时恢复原始数据。
在 Linux 下删除大数据文件中部分字段的重复行并非难事,只要掌握了正确的方法和技巧,并在操作过程中谨慎细致,就能高效、准确地完成任务。
参考来源:相关技术文档和经验分享。